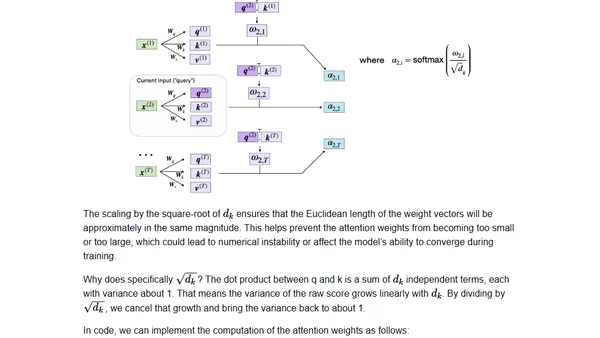
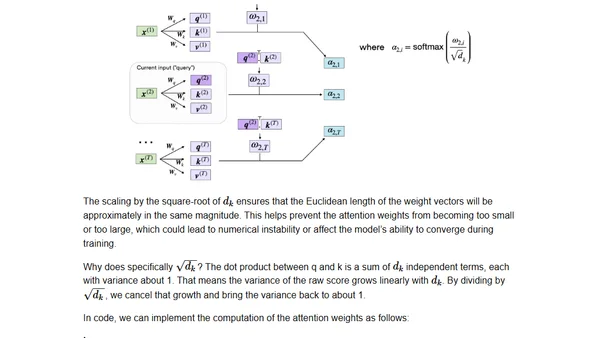
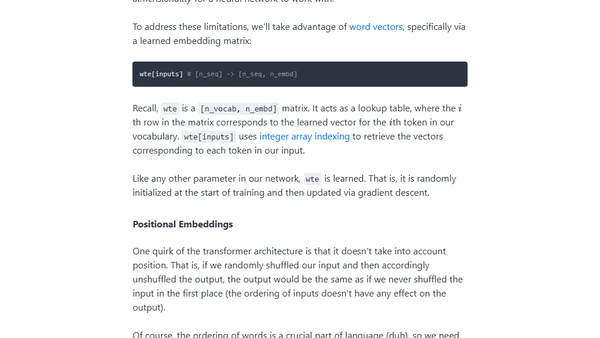
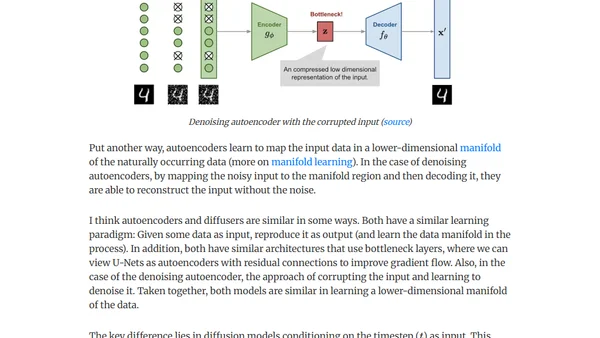
7/11/2024
•
EN
Questions about ARC Prize
An analysis of the ARC Prize AI benchmark, questioning if human-level intelligence can be achieved solely through deep learning and transformers.