
7/28/2026
•
EN
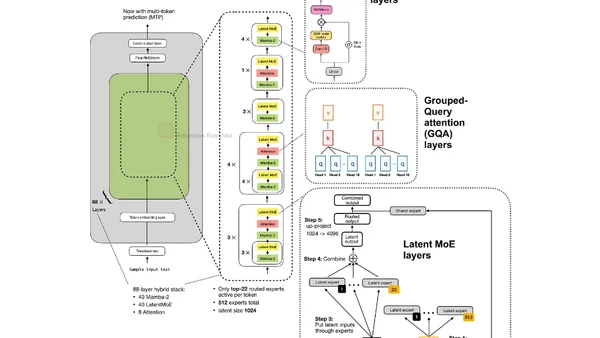
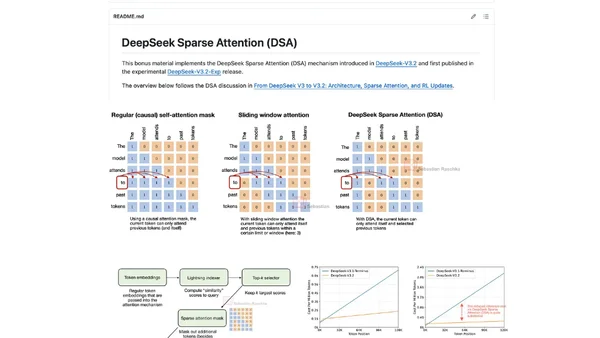
Kimi K3 Architecture Notes
Analysis of Kimi K3's open-weight architecture, focusing on LatentMoE, attention residuals, and NoPE innovations for inference efficiency.