4/20/2026
•
EN
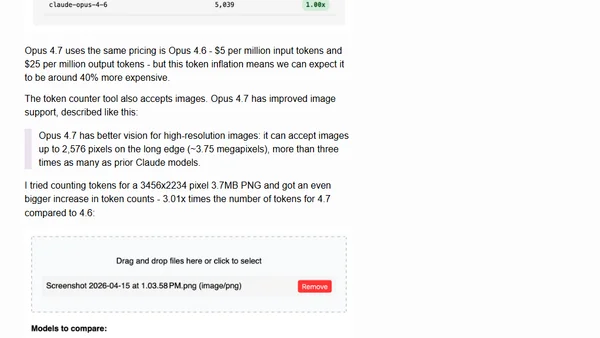
Claude Token Counter, now with model comparisons
Upgraded Claude Token Counter with model comparison, showing token inflation in Opus 4.7 vs 4.6.