5/17/2026
•
EN
2ality blog: temporarily offline
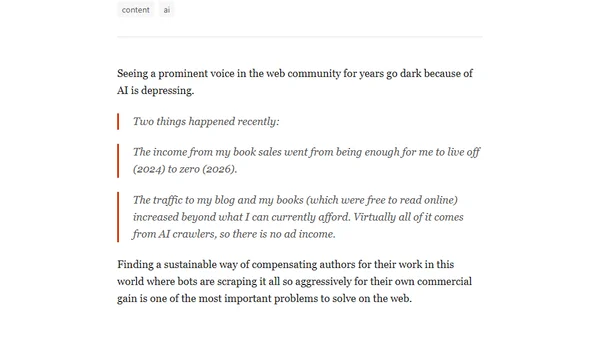
Blogger temporarily takes site offline due to AI crawlers causing unsustainable traffic and loss of income from book sales.