7/22/2025
•
EN
Code Sandbox MCP: A Simple Code Interpreter for Your AI Agents
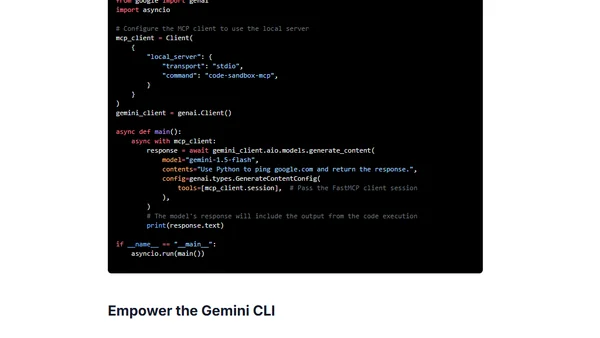
Introducing Code Sandbox MCP, a Model Context Protocol server for safely executing Python and JavaScript code in containers via AI agents.