4/18/2026
•
EN
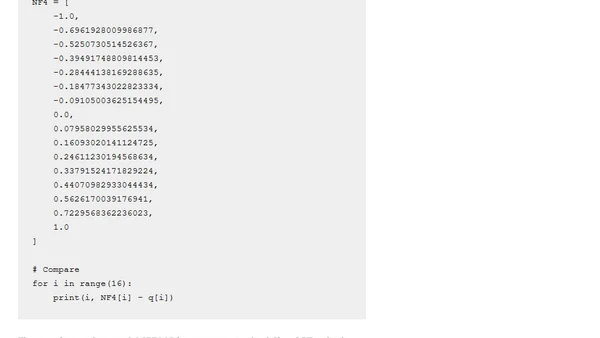
Gaussian distributed weights for LLMs
Explores NF4 and FP4 4-bit floating point formats for LLM weight quantization, focusing on Gaussian-distributed weights.