6/18/2024
•
EN
Deploy Mixtral 8x7B on AWS Inferentia2 with Hugging Face Optimum
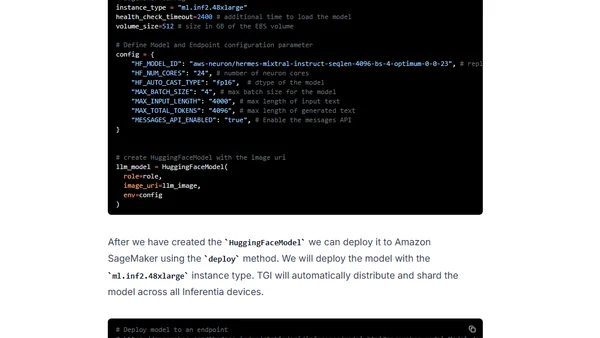
A technical guide on deploying the Mixtral 8x7B LLM on AWS Inferentia2 using Hugging Face Optimum and Amazon SageMaker.