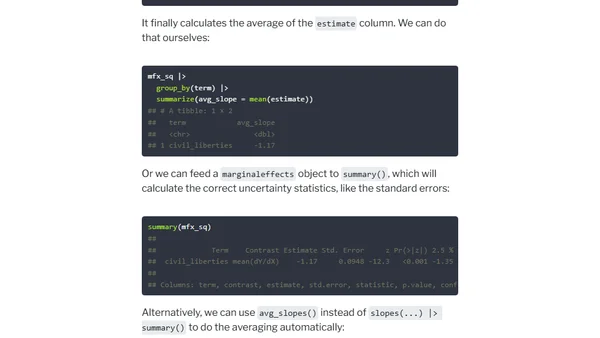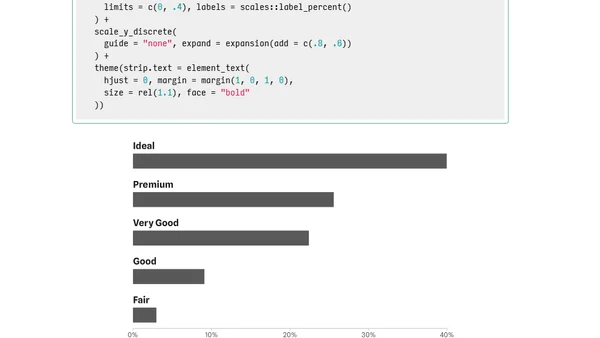
10/26/2023
•
EN
Yet Another How-to on Labelling Bar Graphs in ggplot2
A tutorial on customizing bar chart labels in ggplot2, focusing on placing category labels above bars and styling visualizations.