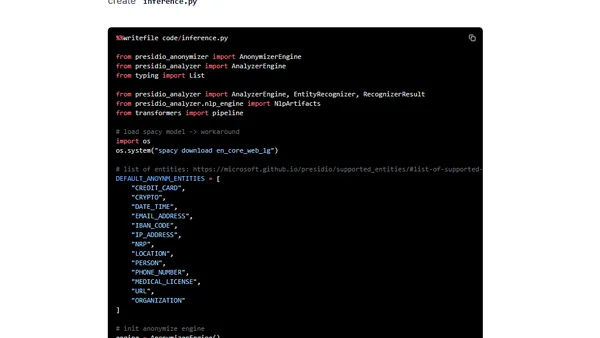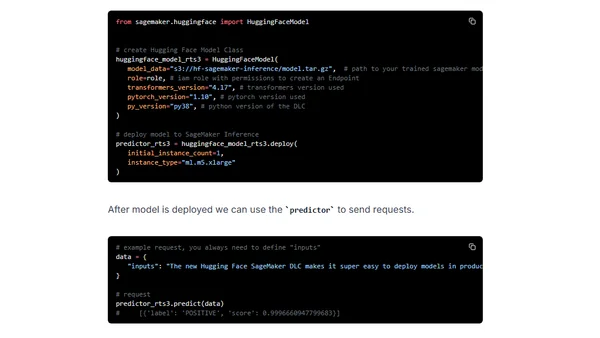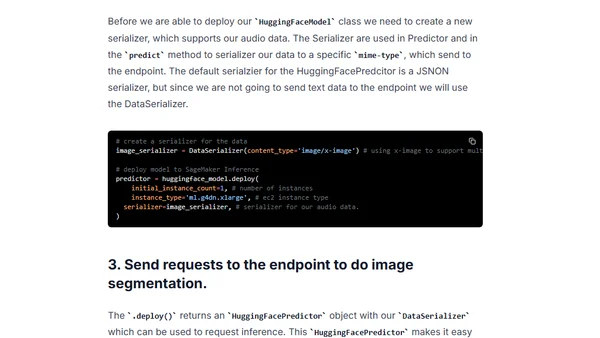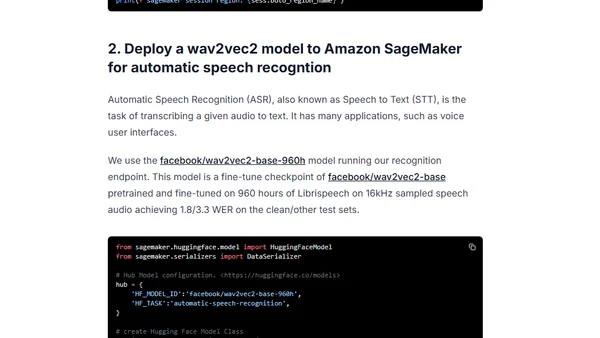
8/16/2022
•
EN
Accelerate BERT inference with DeepSpeed-Inference on GPUs
Learn to optimize BERT and RoBERTa models for faster GPU inference using DeepSpeed-Inference, reducing latency from 30ms to 10ms.