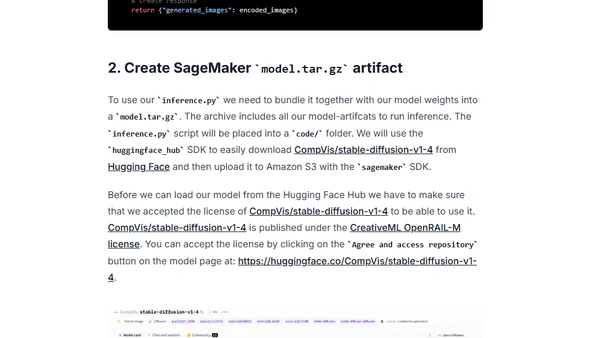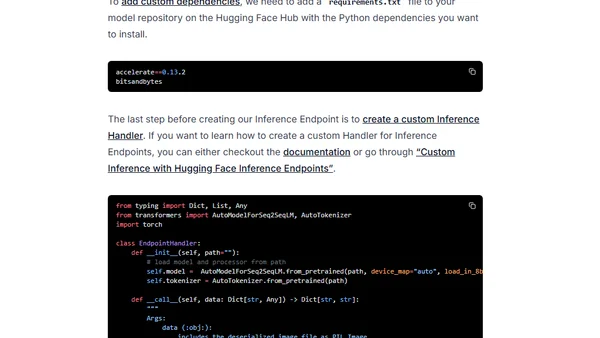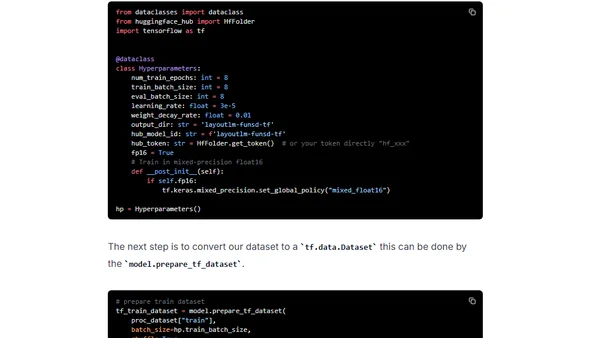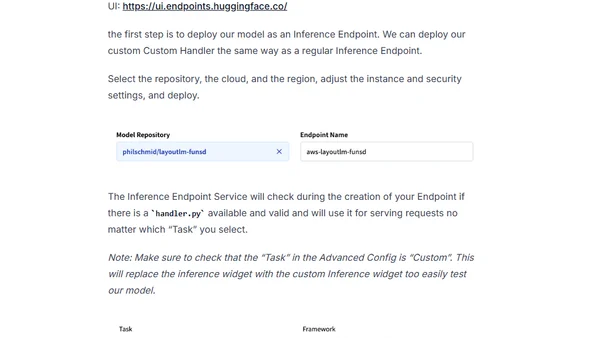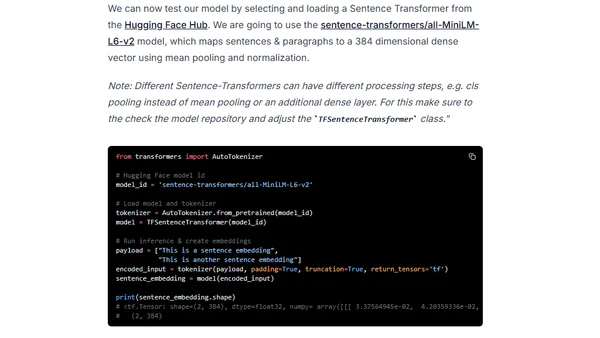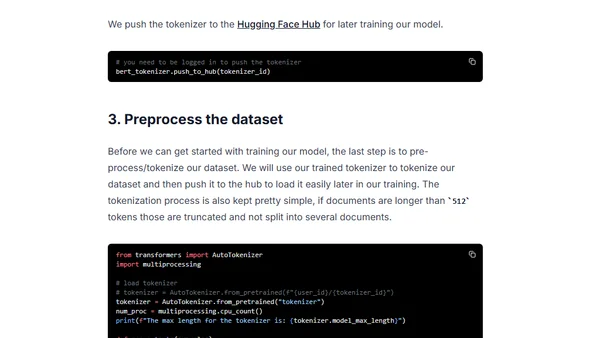
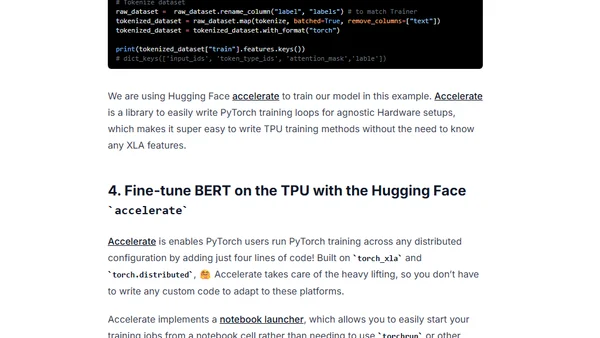
1/16/2023
•
EN
Getting started with Transformers and TPU using PyTorch
A tutorial on fine-tuning a BERT model for text classification using Hugging Face Transformers and Google Cloud TPUs with PyTorch.