12/16/2021
•
EN
Performance and scikit-learn (1/4)
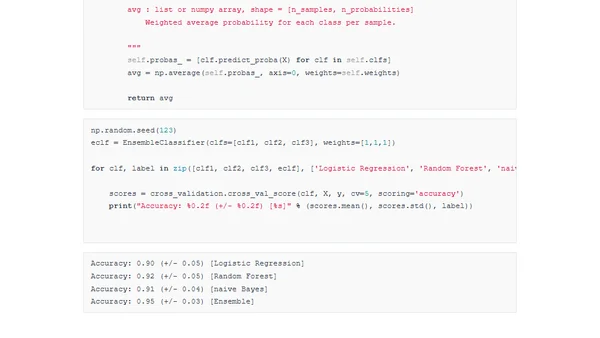
Analyzes performance limitations in scikit-learn due to CPython internals, memory hierarchy issues, and lack of low-level data structures.