![7 New Books added to Big Book of R [7/12/2024]](https://alldevblogs.blob.core.windows.net/thumbs/article-74a3437fb78e-full-9ff738a4.webp)
12/7/2024
•
EN
7 New Books added to Big Book of R [7/12/2024]
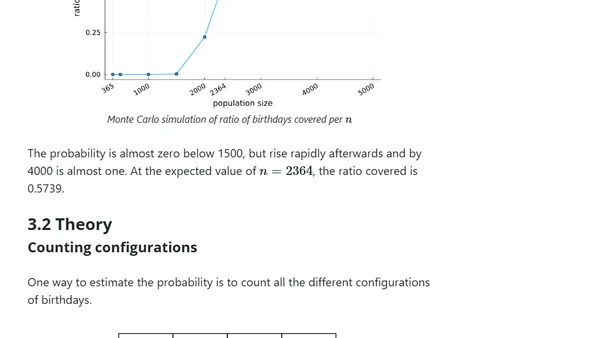
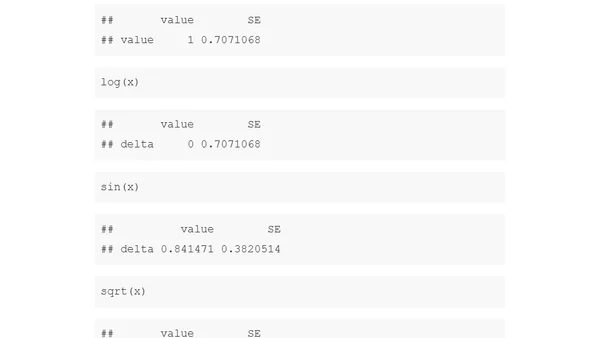
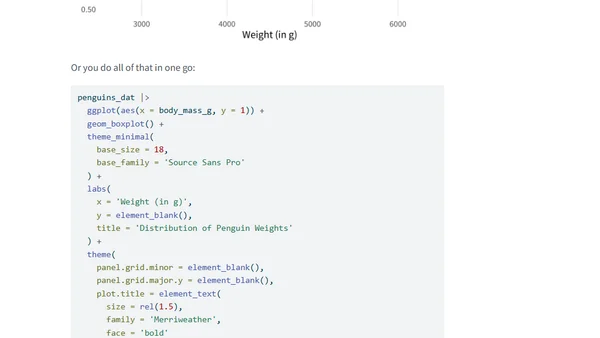
Announces 7 new free R programming books added to the Big Book of R collection, covering topics like machine learning, data science, and software engineering.






![Big Book of R at 400 [New milestone!]](https://alldevblogs.blob.core.windows.net/thumbs/article-12e01710b8e8-full-a2e2e955.webp)




