2/19/2026
•
EN
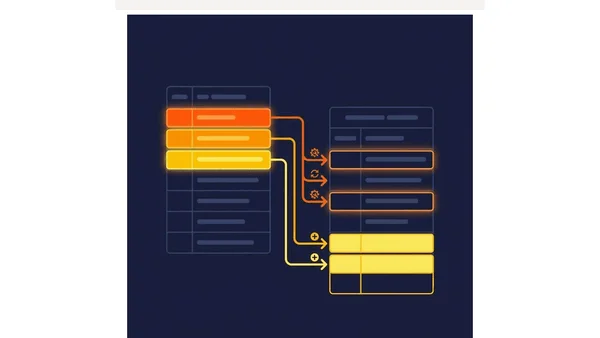
Idempotent Pipelines: Build Once, Run Safely Forever
Explains idempotent data pipelines, patterns like partition overwrite and MERGE, and how to prevent duplicate data during retries.