7/9/2026
•
EN
Have you heard? Clickhouse is winning the observability wars!
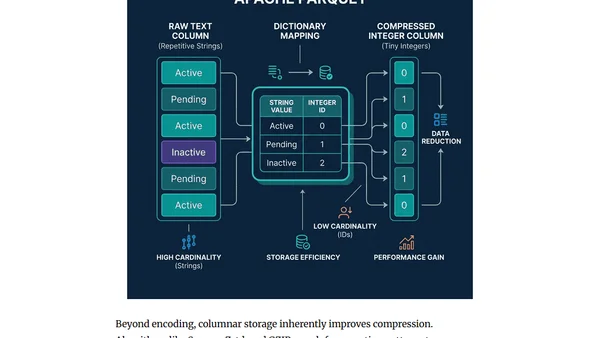
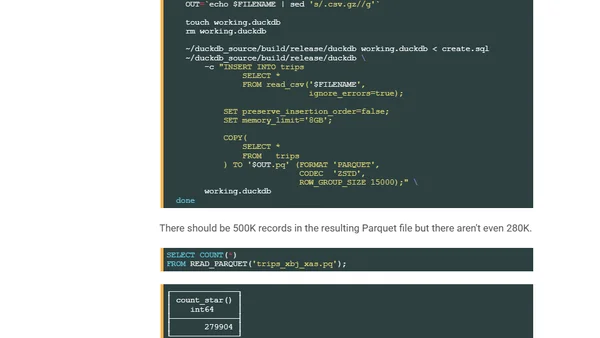
Analysis of why Clickhouse is winning the observability wars with columnar storage, handling massive data scales better than competitors.