6/15/2026
•
EN
RAG Isn't the Problem : Policy as Code Is
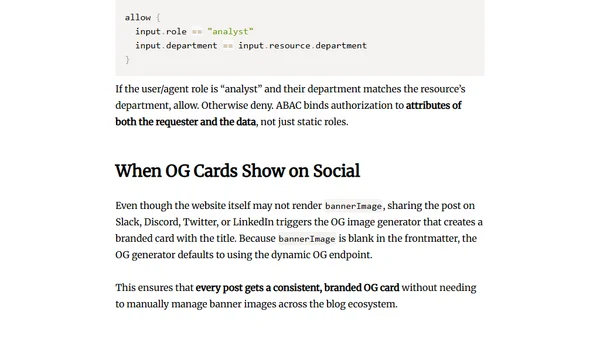
Explains why policy-as-code, not RAG, is the key to secure enterprise AI by embedding authorization into query engines.