5/24/2026
•
EN
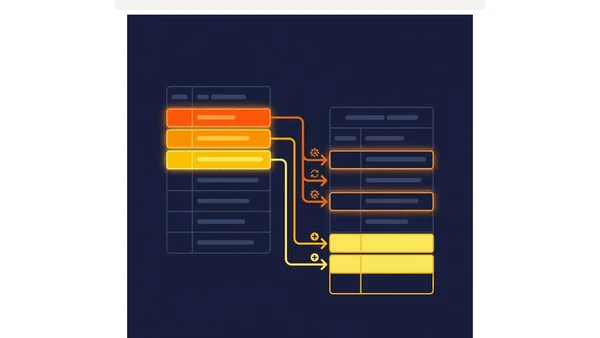
Bringing MLflow and Data Pipelines Closer Together
Explores integrating MLflow 3 with data pipelines for unified observability, covering data lineage, drift detection, and CI/CD for ML.