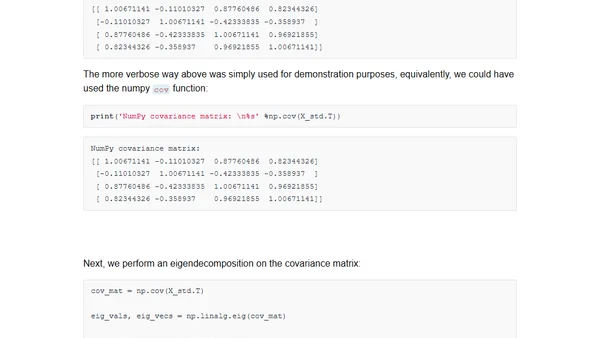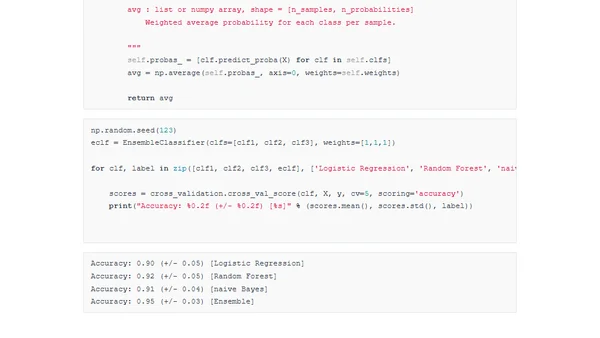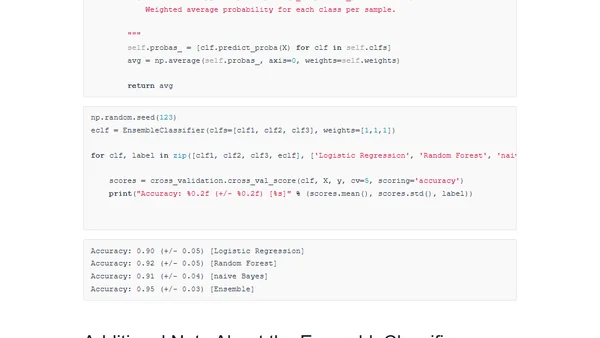
1/27/2015
•
EN
Principal Component Analysis
A tutorial explaining Principal Component Analysis (PCA), a dimensionality reduction technique used in machine learning and data analysis.