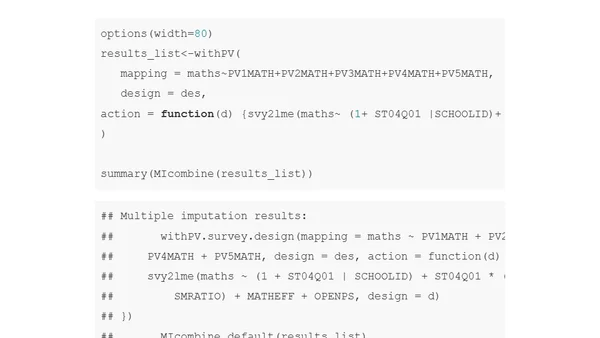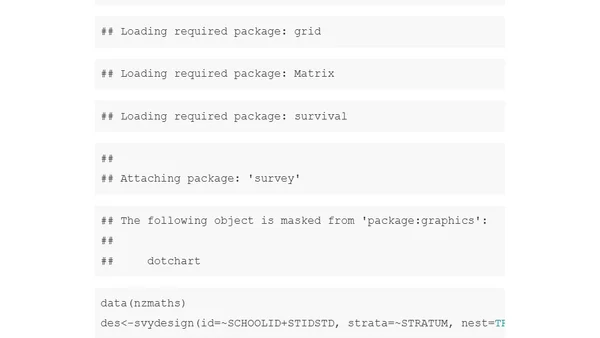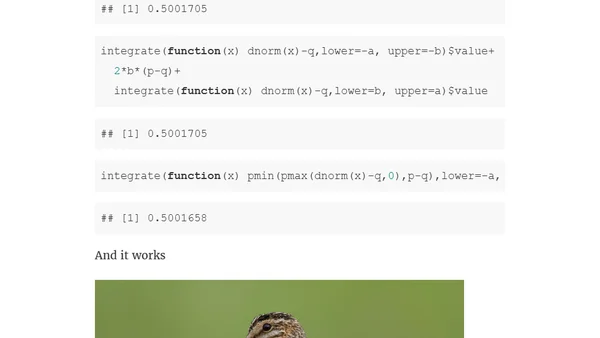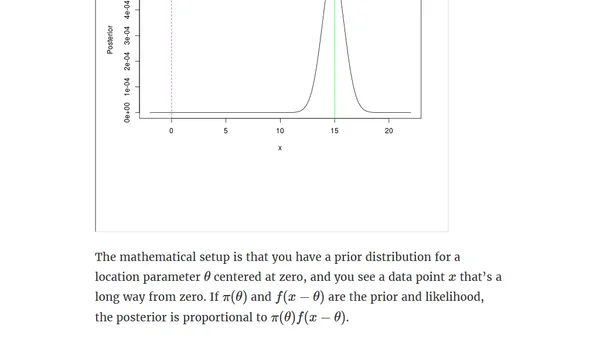
9/10/2019
•
EN
(What’s up with the brackets?)
Explains why parentheses cause R code assignments to print their values, covering invisibility flags and the behavior of the `(` function.