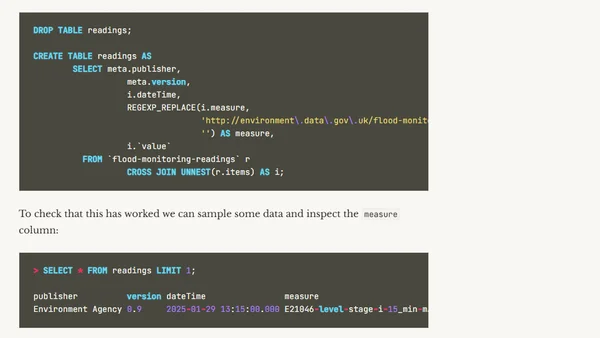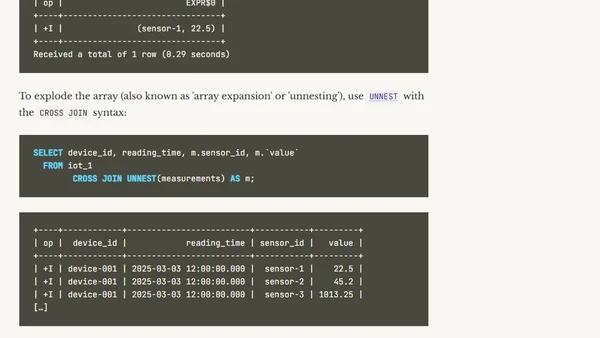
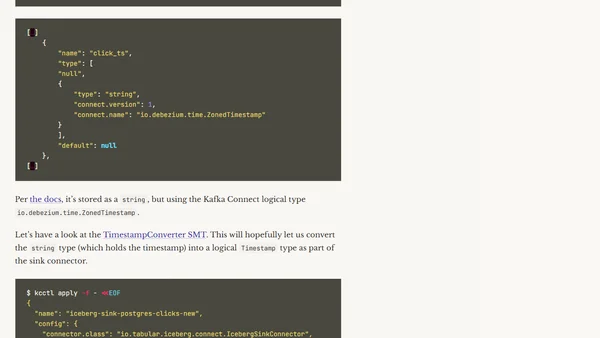
7/4/2025
•
EN
Writing to Apache Iceberg on S3 using Kafka Connect with Glue catalog
A technical guide on using Kafka Connect to write data from Kafka topics to Apache Iceberg tables stored on AWS S3, using the Glue Data Catalog.