Data Wrangling with Flink SQL
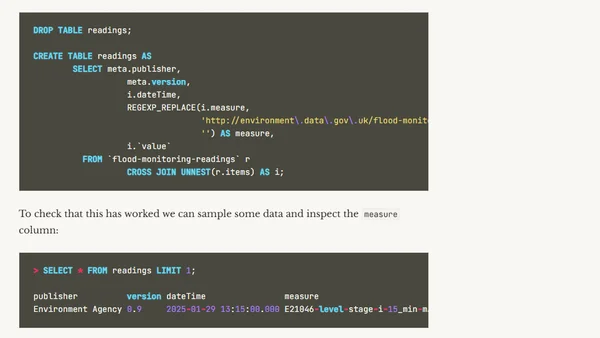
Read OriginalThis article details a hands-on project using Apache Flink SQL to ingest, unnest, and transform data from the UK Environment Agency's flood-monitoring API. It covers creating Flink tables from Kafka topics, handling nested JSON structures with CROSS JOIN UNNEST, and discusses considerations for schema evolution and efficient data pipeline design in a streaming context.
0 comments
Comments
No comments yet
Be the first to share your thoughts!
Browser Extension
Get instant access to AllDevBlogs from your browser
Top of the Week
No top articles yet