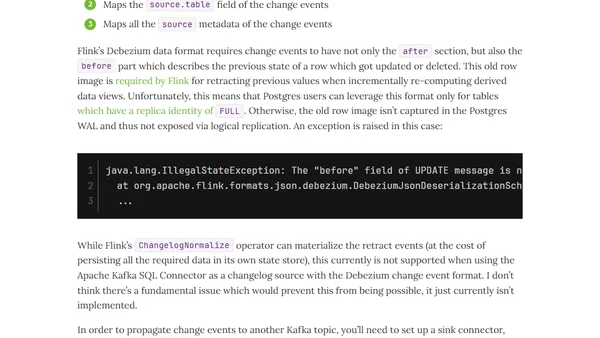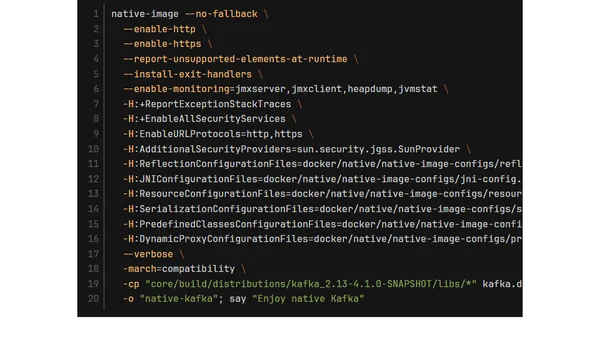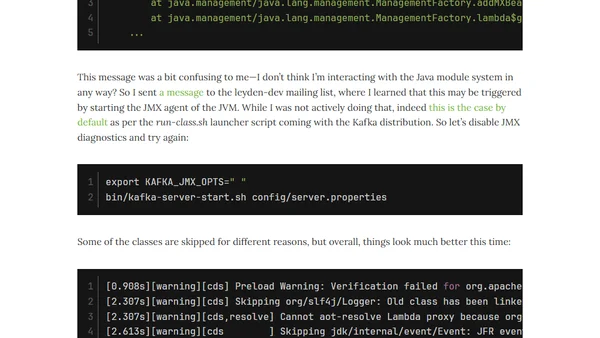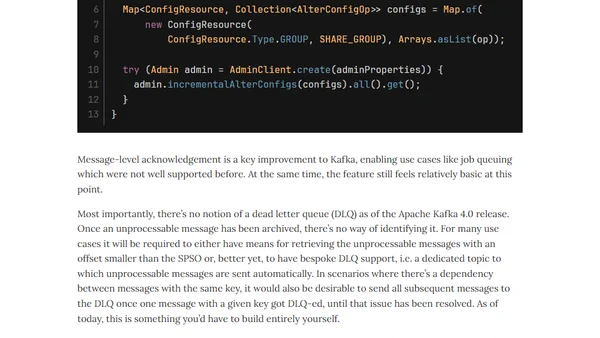
5/31/2026
•
EN
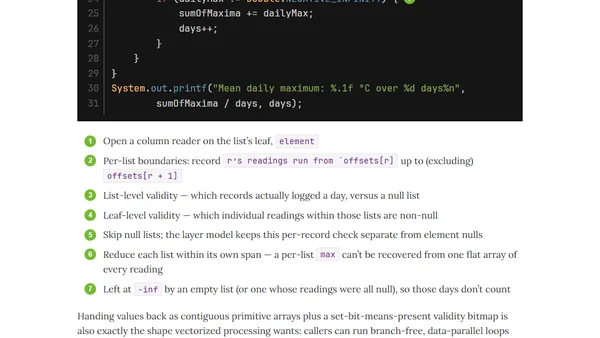
Improved Column Reader API, First Cut of Geospatial Support: Hardwood 1.0.0.CR1 Is Available
Hardwood 1.0.0.CR1 release: improved ColumnReader API for Parquet files, initial geospatial support, and documentation overhaul.