10/13/2018
•
EN
Approximate Distinct Count
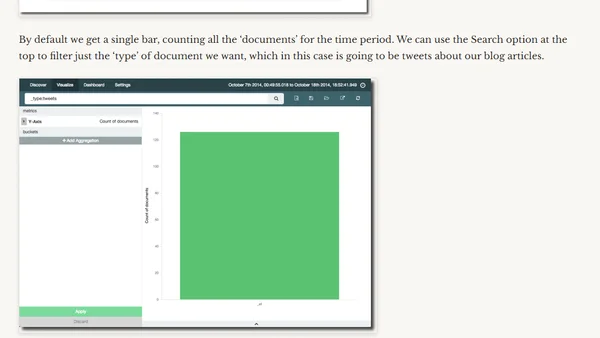
Explains the APPROX_COUNT_DISTINCT function for faster, memory-efficient distinct counts in SQL, comparing it to exact COUNT(DISTINCT).