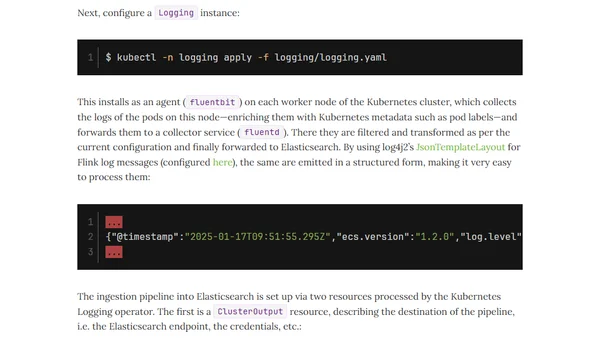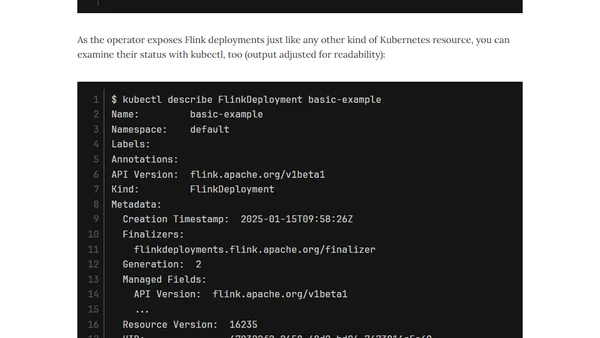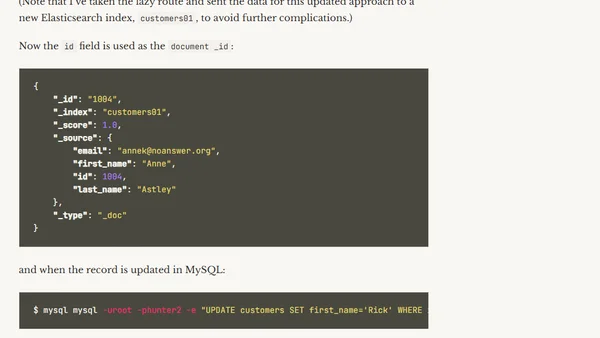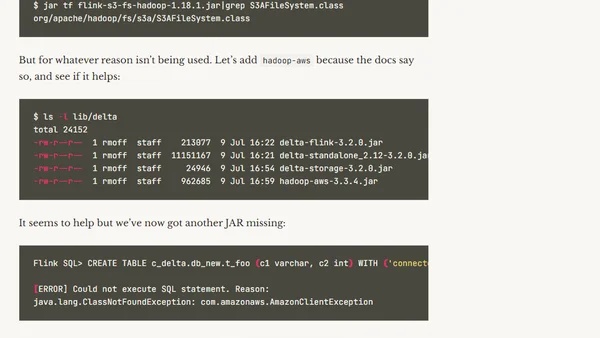
1/28/2025
•
EN
Get Running with Apache Flink on Kubernetes, part 2 of 2
Part 2 of a guide on running Apache Flink on Kubernetes, covering fault tolerance, high availability, savepoints, and observability.