4/25/2014
•
EN
Using SQL Workbench with Apache Hive
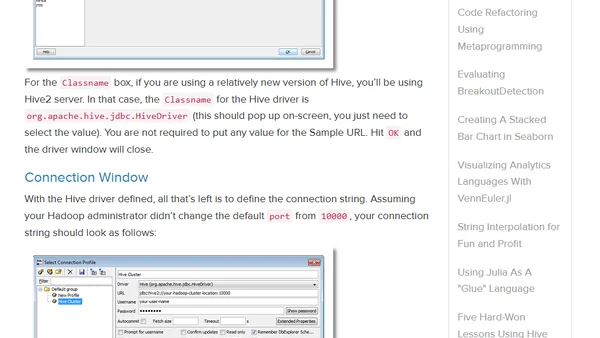
A tutorial on connecting to Apache Hive using the open-source SQL Workbench tool via JDBC, covering driver setup and connection configuration.