4/13/2026
•
EN
What is Apache Parquet? Columns, Encoding, and Performance
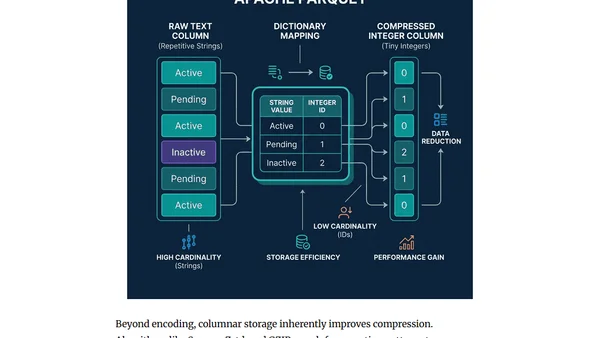
Explains Apache Parquet's columnar architecture, dictionary encoding, and performance benefits for data analytics.