3/6/2026
•
EN
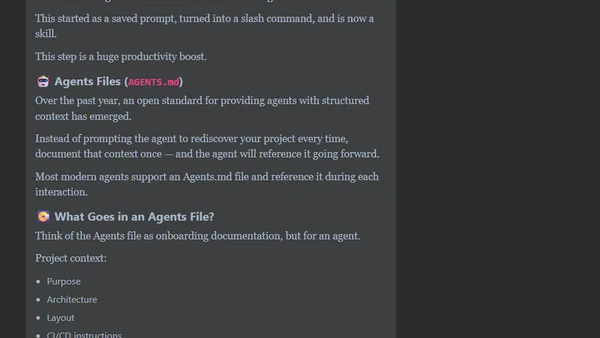
When your coding agent doesn’t understand your project, you’ll get junk
Explains how to improve AI coding agent results by providing project context via an AGENTS.md file.