Running DeepSeek open reasoning models on GKE
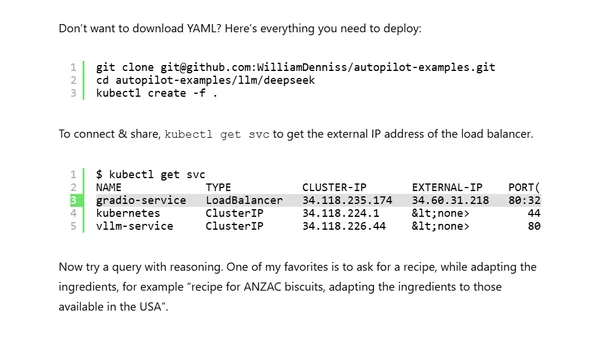
Read OriginalThis article provides a step-by-step tutorial for running DeepSeek's R1 open reasoning models, such as the 8B Llama distilled model, on Google Kubernetes Engine (GKE). It covers creating a GKE Autopilot cluster, setting up secrets for Hugging Face, deploying vLLM for model serving, and creating a custom Gradio application to stream responses and handle the model's unique thinking blocks. The guide includes specific YAML configurations and resource recommendations for GPUs like the Nvidia L4 or A100.
0 comments
Comments
No comments yet
Be the first to share your thoughts!
Browser Extension
Get instant access to AllDevBlogs from your browser
Top of the Week
1
Limit token usage in Microsoft Agent Framework
Jesse Liberty
•
1 votes
2
How to Roll Back AI Agents: Incident Response, Circuit Breakers, and Recovery Patterns
Paul Bryant
•
1 votes
3
Avoiding Reasoning Model Failures with Microsoft Foundry
Luke Murray
•
1 votes
4
When Your AI Agent Lies: Silent LLM Fallbacks
Luke Murray
•
1 votes
5
Adding a custom MCP server to Claude and ChatGPT
Simon Willison
•
1 votes
6
Testing AI prompts and comparing models with promptfoo
Tim Deschryver
•
1 votes
7
Superlogical
Mitchell Hashimoto
•
1 votes