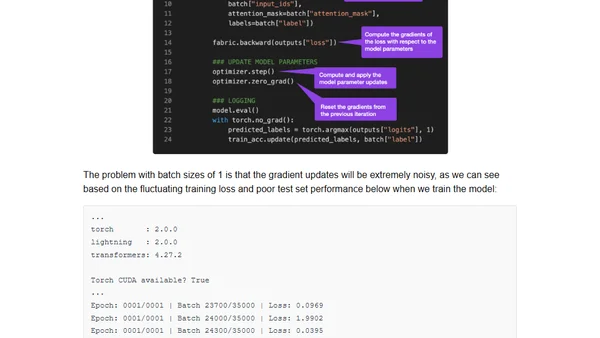
Finetuning Large Language Models On A Single GPU Using Gradient Accumulation
Read OriginalThis technical tutorial explains how to finetune large language models like BLOOM for text classification on a single GPU using gradient accumulation. It addresses GPU memory constraints by accumulating gradients over multiple batches before updating model weights, enabling effective training with limited hardware resources. Includes practical code examples using PyTorch and Hugging Face transformers.
Comments
No comments yet
Be the first to share your thoughts!
Browser Extension
Get instant access to AllDevBlogs from your browser
Top of the Week
No top articles yet