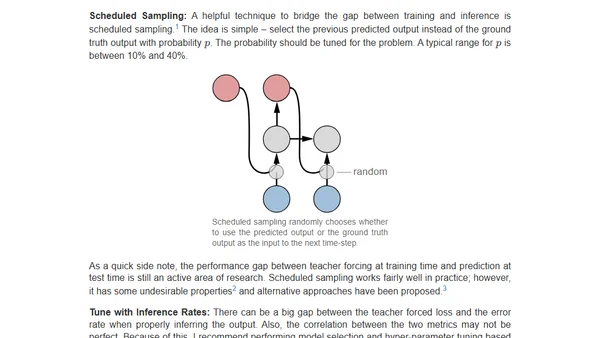

10/3/2021
•
EN
An Introduction to Fisher Information
An introduction to Fisher Information, a statistical concept that quantifies how much information data samples contain about unknown distribution parameters.