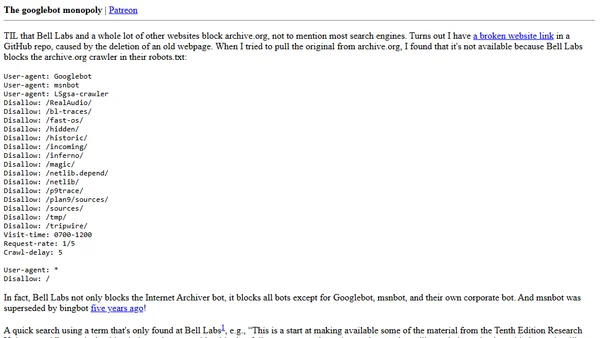
The googlebot monopoly
Read OriginalThe article details the author's discovery that Bell Labs and other websites block most web crawlers, including the Internet Archive's, while allowing Googlebot. This practice, often a default by web developers, inadvertently harms competing search engines and web archives, contributing to a Google monopoly. The piece argues against this misuse of robots.txt and notes that some archives now ignore these blocks.
Comments
No comments yet
Be the first to share your thoughts!
Browser Extension
Get instant access to AllDevBlogs from your browser
Top of the Week
No top articles yet