Scale LLM Inference on Amazon SageMaker with Multi-Replica Endpoints
Read OriginalThis technical tutorial explains how to use Amazon SageMaker's new Hardware Requirements object to deploy multiple replicas of a Large Language Model (LLM), like Llama 13B, on a single instance (e.g., p4d.24xlarge). It covers setup with the SageMaker SDK, configuring the Hugging Face LLM DLC, and deploying models to optimize inference performance and cost.
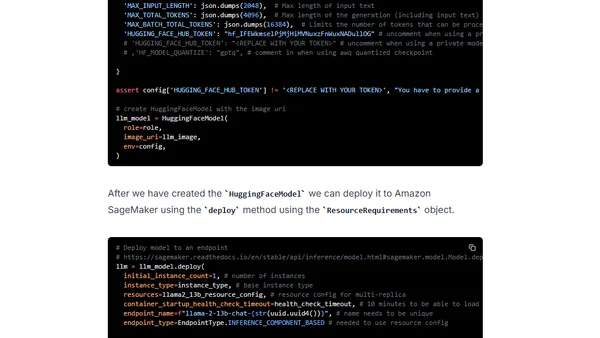
Comments
No comments yet
Be the first to share your thoughts!
Browser Extension
Get instant access to AllDevBlogs from your browser
Top of the Week
1
Limit token usage in Microsoft Agent Framework
Jesse Liberty
•
1 votes
2
How to Roll Back AI Agents: Incident Response, Circuit Breakers, and Recovery Patterns
Paul Bryant
•
1 votes
3
Avoiding Reasoning Model Failures with Microsoft Foundry
Luke Murray
•
1 votes
4
When Your AI Agent Lies: Silent LLM Fallbacks
Luke Murray
•
1 votes
5
Adding a custom MCP server to Claude and ChatGPT
Simon Willison
•
1 votes
6
Testing AI prompts and comparing models with promptfoo
Tim Deschryver
•
1 votes
7
Superlogical
Mitchell Hashimoto
•
1 votes