Kicking the Tyres on Harbor for Agent Evals
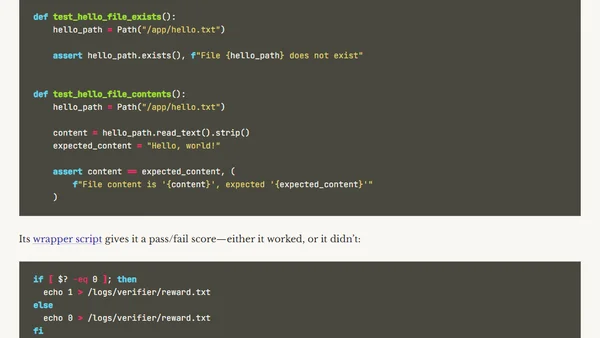
Read OriginalThis article explores Harbor, a framework designed for evaluating and optimizing AI agents and models within container environments. It details how Harbor runs tasks—prompts for coding agents like Claude Code—and scores performance using verifiers. The author tests a 'hello-world' task, explains the dashboard, and mentions plans to use Harbor with dbt. The content is technical, focusing on AI agent evaluation, benchmarking, and containerized testing, relevant to IT/technology and software development.
Comments
No comments yet
Be the first to share your thoughts!
Browser Extension
Get instant access to AllDevBlogs from your browser
Top of the Week
No top articles yet