Jak načíst data do Fabric Lakehouse Pythonem, aniž zabijete F2 kapacitu
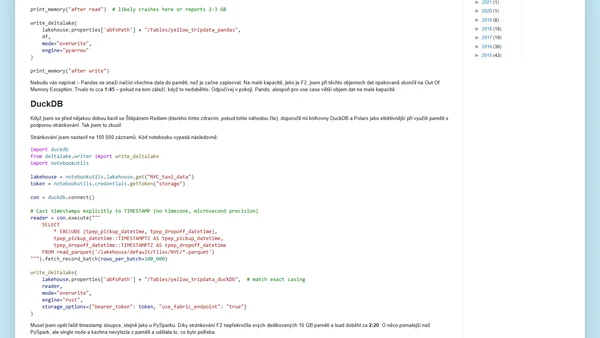
Read OriginalČlánek se zaměřuje na různé způsoby načítání dat do Microsoft Fabric Lakehouse pomocí Pythonu, konkrétně srovnává PySpark, Pandas a další knihovny. Analyzuje jejich dopad na využití kapacity (Capacity Units) a výkon na menších kapacitách (např. F2) na příkladu datasetu New York City Taxi dat. Cílem je najít efektivní metodu, která nepřetěžuje systém.
Comments
No comments yet
Be the first to share your thoughts!
Browser Extension
Get instant access to AllDevBlogs from your browser
Top of the Week
No top articles yet