Ogólnodostępne zbiory danych do Machine Learningu
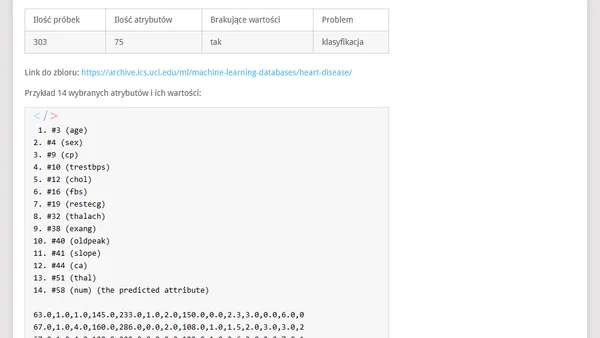
Przeczytaj oryginałArtykuł przedstawia przegląd ogólnodostępnych zbiorów danych do Machine Learningu. Zawiera definicję zbioru danych, wyjaśnia ich typowy format (CSV) i prezentuje szczegółowe opisy popularnych zestawów, zaczynając od klasycznego zbioru Iris. Dla każdego zbioru podano liczbę próbek, atrybuty, typ problemu (klasyfikacja/regresja) oraz link do źródła, co czyni go praktycznym przewodnikiem dla osób rozpoczynających pracę z ML.
Komentarze
Brak komentarzy
Bądź pierwszy, który podzieli się swoimi myślami!
Rozszerzenie przeglądarki
Uzyskaj natychmiastowy dostęp do AllDevBlogs z przeglądarki
Tydzień
No top articles yet